Using Calculated Members in MDX
In Part 1 of this series we looked at some fundamentals on creating MDX views. In this next part, we introduce calculated members and give some basic examples of how to define them and what they can be used for.
What are Calculated Members?
Calculated Members are members derived for a specific purpose and created within the view itself. They do not appear in the cube dimensions e.g. measures.
They are extremely versatile and can be used to show Arithmetic calculations like addition, subtraction, division and multiplication between two or more members or a member and a constant. They can also be used to perform Aggregation functions like aggregate, sum, average, count, minimum and maximum.
In this article, we will introduce calculated members using some Arithmetic functions in the examples. In the next part, we will take this further and look at the Aggregation functions.

Arithmetic Calculated Members
If you are using PAW, this kind of calculated member is easy to add simply by right clicking the base member then clicking Calculation options. You can then name your calculated member and configure the calculation required.
If we want to calculate VAT on Sales Revenue for example, we could create a new member called VAT and multiply our base member by the VAT rate e.g. 0.15 or 15%:
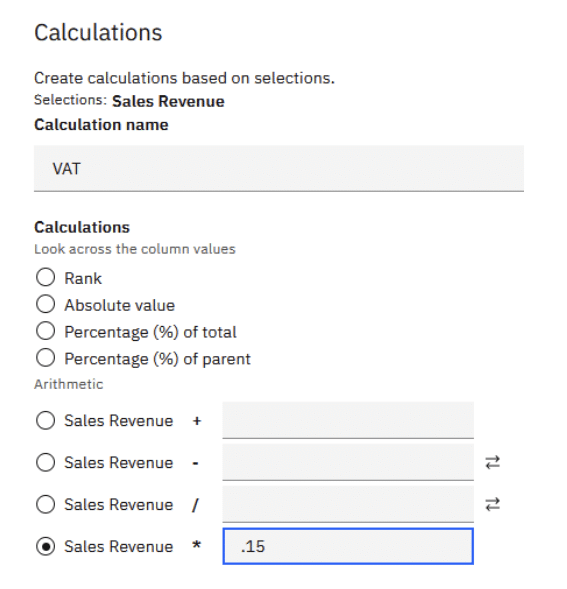
The result would appear as follows in my Sales view:
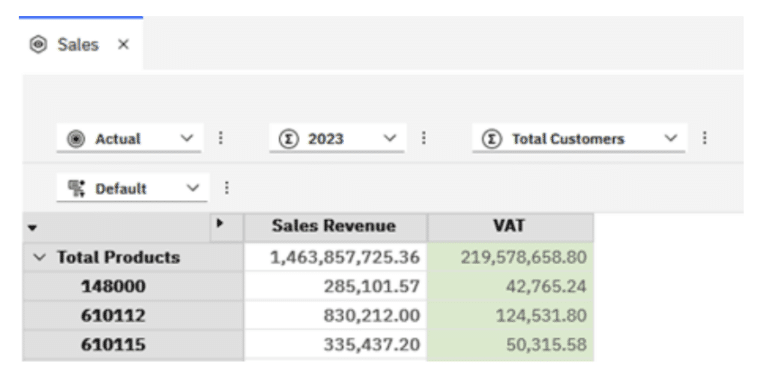
The MDX statement is not too dissimilar to what we looked at previously in Part 1, aside from the first five lines:
WITH
MEMBER [Sales Measures].[Sales Measures].[Total Sales Revenue].[VAT] AS
[Sales Measures].[Sales Measures].[Sales Revenue]*0.15,
SOLVE_ORDER = 1,
FORMAT_STRING = '#,##0.00;(#,##0.00)'
SELECT
NON EMPTY
{[Sales Measures].[Sales Measures].[Sales Revenue],
[Sales Measures].[Sales Measures].[VAT]} ON 0,
NON EMPTY
{DRILLDOWNMEMBER({[Product].[Product].[Total Products]},
{[Product].[Product].[Total Products]})} ON 1
FROM [Sales]
WHERE ([Scenario].[Scenario].[Actual],
[Period].[Period].[2023],
[Customer].[Customer].[Total Customers])
Let’s take a look at the statements and properties responsible for the calculated member we added.
WITH
Tells the MDX to define a temporary calculated member or measure which lasts for the duration of the MDX query. This statement is specified only once when using one or more calculated members.
MEMBER
MEMBER is used to define the name and context of the calculated member. In our example, we added a new member called VAT to our Sales measures.
You will notice that it was referenced as [Sales Measures].[Sales Measures].[Total Sales Revenue].[VAT]. PAW seems to add the calculated member in a hierarchical way with VAT as a subordinate of Total Sales Revenue, in my case. Sales Revenue is a child of Total Sales Revenue and possibly because VAT is based on Sales Revenue, PAW created the calculated member like this.
However, specifying the following works equally well: [Sales Measures].[Sales Measures].[VAT]
The usual limitations apply to naming members. Names are generally case-insensitive but try stick to a standard e.g. proper case or Pascal case if you are removing spaces.
Do not special characters such as +, -, *, /, &, |, ,, ;, {, }, (, ), [, ], <, >, =, and . in member names. Avoid reserved words and ambiguous names where the member already exists as a member in your model.
AS
AS is a keyword that tells MDX to assign the expression or value to the calculated member. In other programming languages, it could be thought of as the equals sign in the following statement:
Let var = x
SOLVE_ORDER
Where queries are complex and there are dependencies between calculated members, you will need to consider using the solve order to prevent sequencing or logical errors, ensuring correct evaluation.
Typically you are unlikely to need to specify or change this if generated by PAW unless you have dependencies that need to be resolved so that their result can be used in the next calculated member.
FORMAT_STRING
The Format_String property allows you to change the default format of values for the calculated member to match a specific format or align to similar members e.g. comma as thousand separator with no decimals.
In our example we had the following: FORMAT_STRING = ‘#,##0.00;(#,##0.00)’
This is a custom format with commas as thousand separator and two decimal places. Negative values defined after the semi-colon, are enclosed in brackets rather than a leading minus sign. This is very similar to Excel formatting and an additional semi-colon could have been added to format zero values e.g. a minus sign or hyphen, like in Excel.
As mentioned in the SOLVE_ORDER section above, you can base members on each other were you need to derive a value based one or more calculated members. This is no different to how you would deal with an existing member in the dimension but you may need to consider the SOLVE_ORDER to ensure dependencies are processed in the correct sequence.
For the next example, we may want to add together the values of Sales Revenue and VAT to yield a total which includes VAT. We simply need to add another member that performs the addition of the two members using the plus (+) operator:
WITH
MEMBER [Sales Measures].[Sales Measures].[VAT]
AS [Sales Measures].[Sales Measures].[Sales Revenue]*0.15,
SOLVE_ORDER = 1,
FORMAT_STRING = '#,##0.00;(#,##0.00)'
MEMBER [Sales Measures].[Sales Measures].[ Total Sales Revenue incl VAT]
AS [Sales Measures].[Sales Measures].[Sales Revenue] +
[Sales Measures].[Sales Measures].[VAT],
SOLVE_ORDER = 1,
FORMAT_STRING = '#,##0.00;(#,##0.00)'
SELECT
NON EMPTY
{[Sales Measures].[Sales Measures].[Sales Revenue],
[Sales Measures].[Sales Measures].[VAT],
[Sales Measures].[Sales Measures].[ Total Sales Revenue incl VAT]} ON 0,
NON EMPTY
{DRILLDOWNMEMBER({[Product].[Product].[Total Products]},
{[Product].[Product].[Total Products]})} ON 1
FROM [Sales]
WHERE ([Scenario].[Scenario].[Actual],
[Period].[Period].[2023],
[Customer].[Customer].[Total Customers])
Note from the above that each new calculated member is defined within the WITH declaration and before SELECT. No commas are used between each of the MEMBER declarations. Each declaration simply starts after the last. In my case I added some formatting for readability.
My view is then updated and shows the following members and values:
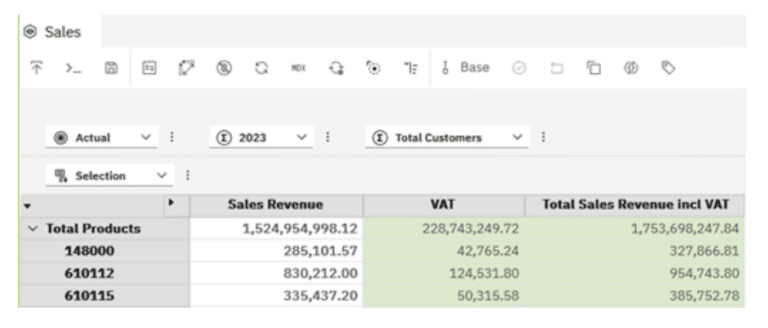
If you are using PAW to add calculated Members, PAW will add additional code using a CASE statement to evaluate members and place the one you defined into the correct position within the displayed set.
If I had a view with Period on the columns to show Sales Revenue across the year and wanted to add 6.75% to the value in March to give an indication of this uplift value, I could right-click in PAW, select Calculation options and add my calculation as [2023-MAR] * 1.0675% for example.
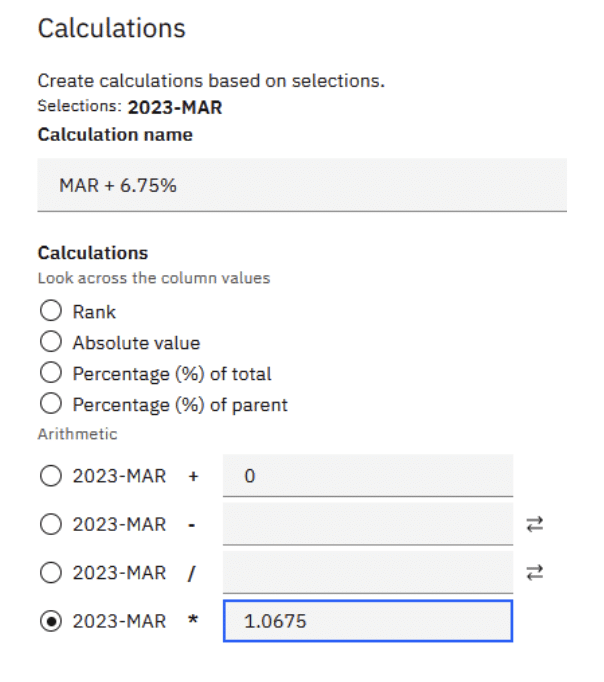
My view would then look like the following:
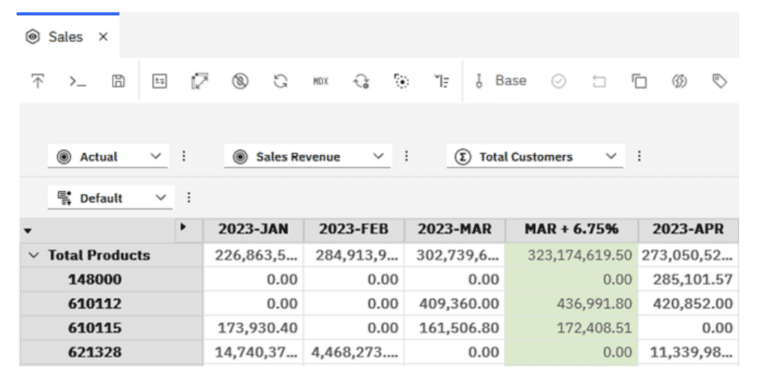
My new calculated member is added after 2023-MAR. However, in this example I am using my set of members called Current Year Periods to specify/driver the members that will be shown on the columns. One would think that the calculated member would be located either before or after the set.
PAW deals with the ordering or positioning by effectively looping through the set and when it finds the correct position, inserts the calculated member there.
The MDX below shows the calculated member called [MAR + 6.75%].
The MDX on the columns gets quite complicated as the Generate function is used to iterate the set and test each member’s name.
When it finds “2023-MAR” as the member name, it inserts both [2023-MAR] and [MAR + 6.75%] into the view, after converting the string to a set. Have a look at the end for further reading links to familiarise yourself with Generate, TM1SubsetToSet and StrToSet.
WITH
MEMBER [Period].[Period].[2023].[MAR + 6.75%]
AS [Period].[Period].[2023-MAR]*1.0675,
SOLVE_ORDER = 1, FORMAT_STRING = '#,##0.00;(#,##0.00)'
SELECT
NON EMPTY
{GENERATE(
{TM1SubsetToSet([Period].[Period],"Current Year Periods","public")},
{StrToSet(
CASE
WHEN [Period].[Period].CURRENTMEMBER.PROPERTIES("MEMBER_NAME") = "2023-MAR"
THEN "{[Period].[Period].[2023-MAR], [Period].[Period].[MAR + 6.75%]}"
ELSE "{[Period].[Period].CURRENTMEMBER}" END
)}
)} ON 0,
NON EMPTY
{DRILLDOWNMEMBER(
{[Product].[Product].[Total Products]},
{[Product].[Product].[Total Products]}
)} ON 1
FROM [Sales]
WHERE ([Scenario].[Scenario].[Actual],
[Sales Measures].[Sales Measures].[Sales Revenue],
[Customer].[Customer].[Total Customers])
That brings up to the end of Part 2 – Using Calculated Members in MDX.
You should now be familiar with what a calculated member is, how to define a simple one programmatically or using PAW. Additionally, you should have an understanding of the keywords that are used in the definition of calculated members and what each is used for.
In the next part of this series we will look into using Aggregate functions like Aggregate, Sum, Average, Minimum and Maximum etc.
MDX Keywords
A summary of the MDX view related keywords used up to now:

Summary of format strings
Numerical Formats
General Number: FORMAT_STRING = ‘General’
Displays the number as is, without any special formatting.
Fixed Number of Decimals: FORMAT_STRING = ‘0.00’
Formats the number to two decimal places. You can adjust the number of zeros after the decimal point to increase or decrease the decimal precision.
Comma as Thousands Separator: FORMAT_STRING = ‘#,###’
Formats the number with commas separating thousands. For example, 1000 would be formatted as 1,000.
Percentage: FORMAT_STRING = ‘Percent’ or FORMAT_STRING = ‘0.00%’
Formats the number as a percentage, optionally specifying decimal precision.
Currency Formats
Currency: FORMAT_STRING = ‘Currency’ or FORMAT_STRING = ‘$#,###.00’
Formats the number as currency, using the dollar sign as the currency symbol. You can replace the dollar sign with another symbol for different currencies.
Date Formats
Short Date: FORMAT_STRING = ‘Short Date’
Formats date values in a short date format, typically MM/DD/YYYY or DD/MM/YYYY depending on locale settings.
Long Date: FORMAT_STRING = ‘Long Date’
Formats date values in a more verbose format, like “Monday, January 1, 2000”.
Custom Formats
Custom Numeric Format: FORMAT_STRING = ‘0.0##’
Displays up to two optional decimal places, showing fewer decimals for whole numbers or numbers with one decimal place.
Scientific Notation: FORMAT_STRING = ‘0.00E+00’
Formats the number in scientific notation with two decimal places.
Conditional Formatting
Positive/Negative/Zero: FORMAT_STRING = ‘0; -0; “Zero”‘
Specifies different formats for positive, negative, and zero values, much like you can do in Excel formatting. In this example, positive numbers are displayed as is, negative numbers are displayed with a minus sign, and zero is displayed as the text “Zero”.
By George Tonkin, Business Partner at MCi.
Further Reading
Part 1 – Learning MDX view in Planning Analytics
Part 2 – Using Calculated Members in MDX
Part 3 – Aggregate Calculated Members in MDX
Part 4 – Using Calculated Members to Add Information
Part 5 – Working with Attributes in MDX Views
Part 6 – Working with Time Series in MDX Views
Part 7 – Using Lookup Cubes to Extend Your Queries
Part 8 – Joining Related Cube Data
Part 9 – Joining Related Cube Data(Part 2)
TM1/Planning Analytics – MDX Reference Guide
Working with Time Related MDX Functions
Discovering MDX Intrinsic Members